تحقیقات
تحقیقات
آموزش Schemas و Schema Registry در Apache Kafka
- توسط : علی حسین شهابی
- 0 نظر
سلام خدمت شما دوستان عزیزم
در آموزش می خواهیم بررسی کوتاهی درباره Apache Avro و Confluent Schema Registry داشته باشیم و کارمون را با این سخت آغار می کنیم :
اگر از Schemas در آپاچی کافک استفاده نمی کنید، زمان زیادی را از دست خواهید داد!
- فیلدی که به دنبال آن است , دیگر وحود نداشته باشد
- type فیلد مورد نظر, عوض شده باشد.(به عنوان مثال قبلا string بوده و الان integeger شده باشد )
خب در این شرایط, برای جلوگیری از اشکال در consumer , معمولا کارهای زیر را انجام می دهیم :
- تمام exception ها را داخل Catch قرار دهیم که این کار به مرور باعث ناخوانایی و زشت شدن کدهایمان شود.
- دیگر هرگز type فیلدها را در producer عوض نکنیم و هر بار دوباره و سه باره چک کنیم تا فیلدی اشتباه ذخیره نشود . در واقع این کاری هست که اکثر شرکت ها انجام می دهند ولی وقتی نفرات کلیدی از شرکت رفتند, دیگر این امنیت نیز از بین خواهد رفت.
- ایجاد یک فرمت و قانون برای نوع فیلدها و تعداد آنها به هنگام produce , که این کار باعث می شود هر وقت لازم بود فیلدها و نوع آنها را با خیال راحتر تر عوض نماییم (بهترین روش همین است)
فرمت های مختلفی مانندCSV, XML, Relational Databases, JSON را از قبل می شناسیم و احتمالا با تمام آنها کار کرده ایم ولی برای کار فعلی ما مناسب نیستند .
در نتیجه فرمتی که می خواهیم به آن بپردازیم , Apache Avro نام دارد.
محبوبیت Avro در جامعه Big data روز به روز در حال افزایش است و به خاطر حمایت کمپانی Confluent یکی از برگزیده ترین و سریع ترین فرمت های serialization می باشد .
در واقع همانطور که در دیتابیس های رابطه ای , شما باید ابتدا یک جدول تعریف کنید و سپس دیتاها را با توجه به ساختار آن جدول, داخل آن قرار دهید, در اینجا هم ابتدا باید یک وقت بگذارید و یک schema ایجاد نموده سپس message های خود را با استفاده از این schema داخل کافکا قرار دهید.
Avro تایپ های زیر را ساپورت می کند :
- تایپ های ابتدایی مثل : int, string, long, bytes, etc…
- تایپ های پیچیده مثل :
enum,arrays,unions, optionals - تایپ های logical مثل :
dates,timestamp-millis,decimal data record مثل : name و namespace
نمونه یک Avro schema :
{
"type": "record",
"namespace": "com.example",
"name": "Customer",
"doc": "Avro Schema for our Customer",
"fields": [{
"name": "first_name",
"type": "string",
"doc": "First Name of Customer"
},
{
"name": "last_name",
"type": "string",
"doc": "Last Name of Customer"
},
{
"name": "age",
"type": "int",
"doc": "Age at the time of registration"
},
{
"name": "height",
"type": "float",
"doc": "Height at the time of registration in cm"
},
{
"name": "weight",
"type": "float",
"doc": "Weight at the time of registration in kg"
},
{
"name": "automated_email",
"type": "boolean",
"default": true,
"doc": "Field indicating if the user is enrolled in marketing emails"
},
{
"name": "registered_ts",
"type": "long",
"doc": "Unix Epoch timestamp in ms at which the user registered"
}
]
}
برای تعریف یک Avro schemas از Json استفاده می کنیم زیرا خیلی از برنامه نویس ها و توسعه دهنده ها با Json آشنا هستند و واقعا ساده می باشد.
داخل آبجکت های Avro , دیتا به همراه اسکیمای آن ذخیره می شود و اگر داخل آبجکتی schema وجود نداشته باشد, آن آبجکت, غیر معتبر می باشد.
هر زمان که لازم بود می توان schema ای که قبلا تعریف کرده ایم را ویرایش و بهبود بدهیم.
مشکلات Avro :
- Avro یک فرمت باینری است. بنابراین، شما نمیتوانید یک فایل Avro را با یک ویرایشگر متنی باز کنید و محتوای آن را همانطور که JSON را مشاهده میکنید, مشاهده نمایید. من به شدت معتقدم که مشاهده یک شیء Avro باید توسط IDE ها در آینده پشتیبانی شود،اما فعلا می توانید از ابزارهای avro-tools استفاده کنید.
- اگر برای اولین بار است که با Avro کار می کنید, ممکن است زمان زیادی از شما بگیرد تا به آن عادت کنید ولی در عوض باعث می شود در آینده وقت خود را صرفه عیب یابی داده هایی که با فرمت اشتباه وارد سیستم شده اند, نکنید
نکته : در حال خاضر فرمت های مختلفی برای serialization وجود دارد و من نمیخواهم بگویم که فرمت X ار فرمت Y بهتر است ولی نکته ای که الان وجود دارد این است که "Confluent Schema Registry " در حال حاضر از فرمت Avro استفاده می کند, پس باید زمان گذاشت و آن را یاد گرفت.
خب حالا که متوجه شدیم Avro چیست و می خواهیم ببینیم چگونه می توان با Avro دیتاهای ورودی را ارزیابی کنیم .
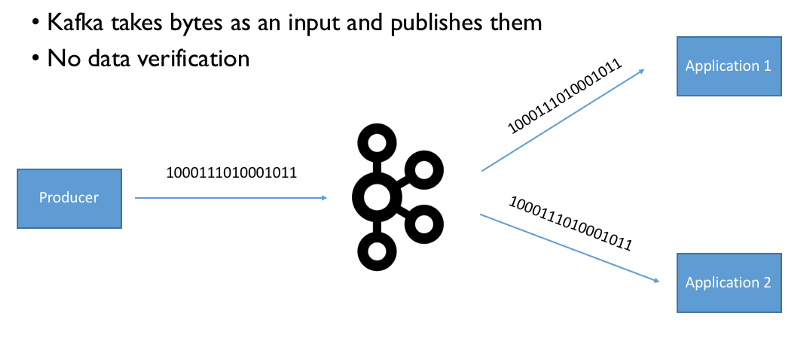
Confluent Schema Registry architecture
"Confluent Schema Registry" در خارج و بیرون از بروکرهای Kafka قرار دارد و می توان گفت که یک کامپوننت اضافی است که قابل نصب و کانفیگ بر روی کلاسترهای Kafka می باشد.
عکس زیر معماری جدید را بعد از ورود "Schema Registry" نشان می دهد
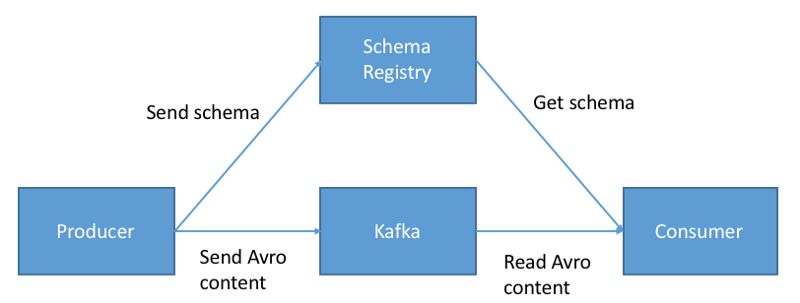
در واقع وقتی از "Schema Registry " استفاده می کنیم مراحل زیر هنگام انتقال یک message جدید به Kafka اتفاق خواهد افتاد :
- ابتدا producer چک می کند آیا اسکیمای مورد نظر در Schema Registry قرار دارد یا خیر و اگر نبود, آن را در Schema Registry ذخیره کرده و در cache قرار می دهد
- وقتی message بخواهد به Kafka ارسال شود, Schema Registry چک می کند آیا اسکیمای آن درست است یا خیر. اگر درست نبود یک exception به producer برگشت داده خواهد شد.
- اگر اسکیما درست بود , producer به همراه محتوای مسیج , "Schema ID" را نیز ضمیمه می کند (کل schema را قرار نمی دهد تا حجم message بالا نرود)
منابع بیشتر برای مطالعه :
خب حالا که با Avro آشنا شدین :در صورتی که علاقه مند هستید می توانید لینک های زیر را نیز دنبال نمایید .
- داکیومنت Avro : داکیونتی خوب و فنی ولی ممکن است در نگاه اول کمی پیچیده به نظر برسد
- Confluent Schema Registry Documentation : توضیحات خوبی داره همچنین مثال هایی هم زده شده
در مقالات بعدی حتما توضیحات جامع تر و علمی تری از کافکا و Avro خواهیم داشت
.jpg)
.jpg)
.jpg)